
사전학습: Decision Tree, 앙상블
https://cheerplay.tistory.com/11
의사 결정 나무 (Decision Tree)
- 의사 결정 나무 (Decision Tree) 의사 결정 나무는 의사결정 규칙(Decision rule)을 나무구조로 도표화하여 관심대상이 되는 집단을 몇 개의 소집단으로 분류(Classification)하거나 예측(Prediction)을 수행
cheerplay.tistory.com
https://cheerplay.tistory.com/14
[머신러닝] 앙상블(Ensemble)
- 앙상블(Ensemble) 어떤 데이터를 학습할 때, 여러 개의 모델을 조화롭게 학습 시켜 그 모델들의 에측 결과들을 이용하여 더 정확한 예측 값을 구할 수 있다.- 앙상블(Ensemble) 종류Bagging(Bootstrap Aggre
cheerplay.tistory.com
- Random Forest
- 랜덤 포레스트(Random Forest)는 앙상블(Ensemble) 학습의 한 종류로, 배깅(Bagging) 기법을 활용한 대표적인 알고리즘이다.
- 여러 개의 결정 트리(Decision Tree)를 조합하여 더 강력한 분류 모델을 구축하는 방법이다.
- 쉽게 말해, Decision Tree가 모여서 더 좋은 결과를 내는 모델이라고 생각하면 된다.

- 아이디어: Random Forest는 Decision Tree(DT) 하나가 Training data에 너무 쉽게 overfit되고 training data의 변화에 민감하다면 DT를 여러개 사용해서 다수결을 하는 방식으로 보완하자는 아이디어를 제시한다.
- 별거 아닌 것 같은데, practical하게 굉장히 좋은 성능을 보여준다.
- 이렇게 단일 모델을 여러개 모아서 더 좋은 판단을 하는 방법론을 Model Ensemble이라고 한다.
- Not Decision Forest but Random Forest
- Decision Tree를 모으기만 하면 더 좋은 결과를 낼 수 없다.
- 같은 데이터에 대해서 만들어진 Decision Tree는 같은 결과를 출력한다.
- 왜냐면, best split 지점이 매번 같게 뽑히기 때문이다!
- 따라서 조금 더 다양성이 필요하다
- 다양성 확보
- Bagging(Bootstrap Aggregating)
- 원본 데이터 셋에서 랜덤하게 샘플한다. (모집단 자체를 바꾼다)
- Random Subspace Method
- feature sampling (Decision Tree가 뽑는 feature를 바꾼다)
- Bagging + Random Subspace Method을 통해서 만들어진 각 Decision Tree에 다양성을 부여한다.
- Bagging(Bootstrap Aggregating)
- 정리
- 다양성을 가진 여러개의 Decision Tree들의 결론을 다수결로 평가(Aggregating)하는 것으로 "집단 지성"을 구현할 수 있다.

- Random Forest는 그냥 Decision Tree들을 모으는게 아닌, randomness를 적당히 포함하는 것으로 Decision Tree의 약점을 잘 보완한 모델이다.
- 정형 데이터를 머신러닝으로 수행할 때 굉장히 좋은 baseline model이 된다. (만만하게 잘되는 모델)
- Feature Importance Score
- Random Forest를 수행 후 어떤 Feature가 중요한지 확인하기
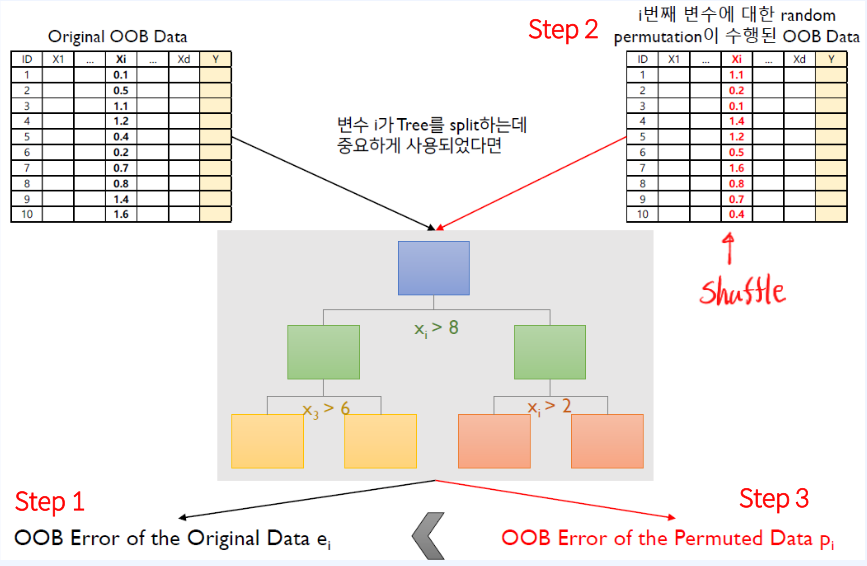
용어:
- OOB(Out Of Bag): OOB Data는 Bootstrap을 통한 랜덤으로 중복추출 했을 때 train 데이터에 속하지 않는 데이터
Feature Importance Score: X_i 번째 데이터에 집중하여 X_i Feature 중요도를 판단하는 방법
- X_i 번째 데이터에 집중하자.
- e_i (OOB error): Original OOB Data에서 X_i 번째가 정상적인 Data로 이를 이용하여 모델의 오차
- p_i (Permutation error): random permutation이 수행된 OOB Data는 X_i 번째의 순서를 shuffle한 것을 사용한 모델의 오차
결론: e_i < p_i 이면 X_i 번째 feature은 중요한 변수이다.
- 이유: 당연하게도 중요한 feature의 변수가 랜덤하게 바꼈으니 모델의 성능에 큰 영향을 줬을 것이다.
- 반대로, e_i >= p_i 이면 중요하지 않은 변수이다. 왜? -> i번째 feature가 중요하지 않았기 때문에 모델에 성능에 큰 영향을 안줬기 때문이다.

- estimators=4일 때 예를 들자
- 4개의 DT가 다 e_i < p_i 일 때의 평균 값을 d_i(평균) 라고 하자.
- 4개의 DT가 다 e_i < p_i 일 때의 분산 값을 s_i 라고 하자.
- X_i Feature Importance Score = di(평균) / s_i
- score가 높다는 것은 e_i < p_i 평균이 크고 4개의 DT간의 분산이 작다는 것으로 이 변수의 중요도가 높다는 것을 뜻한다.
- Feature importance 활용:
- 어떤 Feature가 중요한지 확인만 했지, 해석력은 Random Forest에서 없다.
- 이러한 Feature을 Decision Tree를 이용하여 어느지점에서 split 되는지 확인할 수 있는 해석력을 확인할 수 있다.
- 코드실습
- Hyperparameter tuning
- n_estimators
- max_depth
- Random Forest는 이 두개만 조절해도 좋은 결과를 얻을 수 있다.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
from sklearn.metrics import confusion_matrix, f1_score
import matplotlib.pyplot as plt
import seaborn as sns
# Data Loading (수술 時 사망 데이터)
data = pd.read_csv("https://raw.githubusercontent.com/GonieAhn/Data-Science-online-course-from-gonie/main/Data%20Store/example_data.csv")
# X & Y Split
Y = data['censor']
X = data.drop(columns=['censor'])
idx = list(range(X.shape[0]))
train_idx, valid_idx = train_test_split(idx, test_size=0.3, random_state=42)
rf_model = RandomForestClassifier(n_estimators=50, max_depth=15, random_state=42,
criterion='gini', max_features='auto',
bootstrap=True, oob_score=False)
rf_model.fit(X.iloc[train_idx], Y.iloc[train_idx])
# Train Acc
y_pre_train = rf_model.predict(X.iloc[train_idx])
cm_train = confusion_matrix(Y.iloc[train_idx], y_pre_train)
print("Train Confusion Matrix")
print(cm_train)
print("Train Acc : {}".format((cm_train[0,0] + cm_train[1,1])/cm_train.sum()))
print("Train F1-Score : {}".format(f1_score(Y.iloc[train_idx], y_pre_train)))
print("-----------------------")
# Test Acc
y_pre_test = rf_model.predict(X.iloc[valid_idx])
cm_test = confusion_matrix(Y.iloc[valid_idx], y_pre_test)
print("Test Confusion Matrix")
print(cm_test)
print("TesT Acc : {}".format((cm_test[0,0] + cm_test[1,1])/cm_test.sum()))
print("Test F1-Score : {}".format(f1_score(Y.iloc[valid_idx], y_pre_test)))
feature_map = pd.DataFrame(sorted(zip(best_model.feature_importances_, X.columns), reverse=True), columns=['Score', 'Feature'])
# Importance Score Top 10
feature_map_20 = feature_map.iloc[:10]
plt.figure(figsize=(20, 10))
sns.barplot(x="Score", y="Feature", data=feature_map_20.sort_values(by="Score", ascending=False), errwidth=40)
plt.title('Random Forest Importance Features')
plt.tight_layout()
plt.show()
'ML' 카테고리의 다른 글
| [Boosting] Light GBM (0) | 2024.07.24 |
|---|---|
| [머신러닝] 앙상블(Ensemble) (1) | 2024.06.01 |
| 로지스틱 회귀 (Logistic Regression) (0) | 2024.06.01 |
| 의사 결정 나무 (Decision Tree) (1) | 2024.05.30 |